Hallo Leo,
Dateien bestehen eigentlich nur aus Zahlen (Bits).
Nun kann man z.B. den Zahlen von 0…255 Buchstaben, Ziffern, Satzzeichen, Steuerzeichen usw. zuordnen. Jetzt gibt es verschiedene Tabellen, welchem Wert, welcher Zeichen zugeordnet ist, Lange Zeit waren ASCII und EBCDIC sehr verbreitet.
Hier eine Tabelle, welche EBCEDIC und ASCII enthält. in der linken Spalte ist der Zahlenwert. In der rechten Spalte dann das EBCEDIC-Zeichen, welches auf dem Bildschirm erscheint, bzw. das Steuerzeichen. In der mittleren Spalte ist der Zahlenwert, welcher in ASCII für das Zeichen verwendet wird.
Du kannst leicht sehen, dass ein in ECBDIC geschriebener Brief in ASCII nicht lesbar ist.
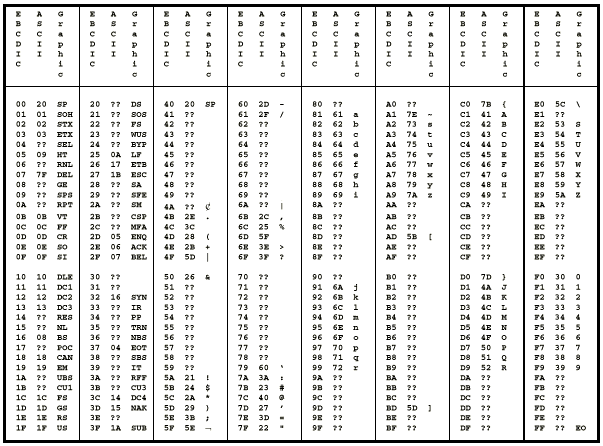
Z.B. ist 0x40 in EBCDIC ein Leerschlag (SPace) in ASCII ist 0x40 das Zeichen @, welches in EBCDIC den Wert 0x/C hat.
Mittlerweile wird oft UTF verwendet. UTF-(, mit 8 Bits pro Zeichen entspricht in etwa ASCII. Nun sind aber nicht alle Schriften lateinisch wie unsere, weshalb es noch UTF-16 und UTF32 gibt. In UTF gibt es dann auch Zeichensätze für Klingonisch und ägyptische Hieroglyphen.
TIFF ist ein Bildformat. Hier geben die Zahlen die Farbe für die Bildpunkte an. Damit man das Bild wieder zusammenbauen kann, sind vorne noch angaben zum Bildformat (xx * yy, Pixel) und Angaben wie die Farben codiert sind.
PDF- und z.B. Word-Dateien sind noch etwas komplexer. Der Text selbst ist meistens UTF codiert. Dazwischen befinden sich dann Angaben zur Formatierung, Zeichensatz und auch zum einbinden anderer Dateien. Word kann noch verweise auf Programme einfügen, deren Ausgabe im Text eingesetzt werden (z.B. ein Graphik, welche mir Excel erstellt wird.) Bilder werden eben auch im Bildformat zwischen dem Text eingefügt.
Ein weiteres verbreitetes Format sind Programme. Hier stehen die Zahlenwerte für Befehle, welche die CPU dann ausführt.
Du musst also deine TIFF-Dateien zuerst in Text-Dateien umwandeln. Dies geht über OCR (Optical Character Recognition, Optische Zeichenerkennung). Dies sind spezielle Programme, welche heute eigentlich mit allen Scannern mitgeliefert werden.
Allerdings musst du das Ganze nachbearbeiten!
Bei einer sehr guten Erkennungsrate musst du vielleicht 5-10% der Zeichen nachbearbeiten. z.B. sind c und o für den Computer nicht immer eindeutig verschieden.
Falsche Buchstaben nützen dir beim Suchen nichts. 
Hier zeigt sich wieder einmal die, noch. Überlegenheit des Menschlichen Gehirns. In einem Text erkennst du ein Wort nicht nur an den Buchstaben, wie ein Computer. Aus dem Kontext heraus ergeben manche Worte auch keinen Sinn. Du kannst also euch ein Wort erkennen, das falsch geschrieben ist oder einzelne Buchstaben nicht erkennbar sind. Ein Computer versteht ab den Text (noch) nicht.
Aus „ich bin Müde“ kann der locker „Iho bln Mude“ machen.
MfG Peter(TOO)

