Hallo in die Runde!
Vor einiger Zeit habe ich mir ein Monitoringsystem für die Server und Arbeitsplatzrechner in unserem Unternehmen gebaut. Das läuft auch ganz gut, aber mittlerweile ist die Datenbank dahinter etwa 3,5GB groß und die Antwortzeiten bei Anfragen ziemlich lang. Der SQL-String für die Abfragen sieht so aus:
SELECT * FROM tblstatus WHERE (SQLZEIT IN (SELECT DISTINCT MAX(SQLZEIT) FROM tblstatus GROUP BY FIRMA, COMPUTER)) and (SQLZEIT >= ‚20200416‘) ORDER BY FIRMA, COMPUTER;
Nun zu meiner Frage: Wie kann diese Abfrage auf Geschwindigkeit optimiert werden?
Hallo und danke für die Antwort. Damit bekomme ich nur FIRMA, COMUTER und SQLZEIT. Ich brauche aber alle Felder des Datensatzes. Deshalb die „teure“ Variante.
G
moin moin,
und wieder danke für die antwort, aber genau das funktioniert nicht. deshalb ja die anfrage hier in die große runde. ich möchte die kompletten aktuellsten datensätze (SQLZEIT) für alle GROUP BY nach FIRMA und COMPUTER haben. nach meinem (begrenzten) wissensstand ist das wohl nur über das indizierte sql-statement möglich. aber da gibt es doch hoffentlich noch verbesserungspotenzial. bin für alle vorschläge offen.
g
Naja, ich gehe mal davon aus, daß in den anderen Feldern Status-Infos wie Festplattenbelegung etc. stehen. Danach will man nicht gruppieren, aber man darf diese Spalten auch nicht einfach hinter das SELECT schreiben.
Zur eigentlichen Frage:
Du hast nen Index auf SQLZEIT, FIRMA und COMPUTER? Allein das kann deine Abfrage um eine gaaanz kleine Winzigkeit beschleunigen.
Das ist deine originale Abfrage:
SELECT *
FROM tblstatus
WHERE (SQLZEIT IN (
SELECT DISTINCT MAX(SQLZEIT) FROM tblstatus GROUP BY FIRMA, COMPUTER)
)
and (SQLZEIT >= ‚20200416‘)
ORDER BY FIRMA, COMPUTER;
Vom reinen Verständnis her:
Es wird eine Liste der neuesten Zeitstempel für jeden Computer in jeder Firma erstellt, und dann werden alle Zeilen angezeigt, deren Zeitstempel in dieser Liste sind, und die neuer als April sind.
Ich sehe da schonmal einen Bug. Wenn zwei Computer gestern genau gleichzeitig einen Eintrag in die DB geschrieben haben, und der zweite sich heute noch nicht gemeldet hat, dann ist der gestrige Zeitstempel in der Liste. Und damit wird vom ersten Computer, der heute bereits einen neuen Eintrag abgelegt hat, sowohl der heutige als auch der gestrige Eintrag angezeigt… War das der Grund für das DISTINCT, das hier einfach mal gar nichts macht? Und ist das überhaupt ein Problem?
Jetzt zur Performance:
Theoretisch wird für jeden einzelnen Eintrag in der Tabelle die o.g. Liste erneut erzeugt. Datenbanken sind aber gut im Optimieren von Abfragen, daher sollte hoffentlich erkannt werden, daß die innere Abfrage immer das gleiche Ergebnis liefert. Allerdings weiß die innere Abfrage ggf. nichts davon, daß später nur die Einträge seit April gewünscht werden. Es würde daher ggf. erheblich etwas bringen, die April-Bedingung mit in die innere Abfrage zu packen.
Ich hätte es aber vermutlich so gemacht:
WITH
a (t, c, f) as (SELECT
MAX(SQLZEIT),
COMPUTER,
FIRMA
FROM tblstatus
WHERE SQLZEIT >= ‚20200416‘
GROUP BY FIRMA, COMPUTER)
SELECT *
FROM tblstatus
RIGHT JOIN a ON (a.t = tblstatus.SQLZEIT
AND a.c = tblstatus.COMPUTER
AND a.f = tblstatus.FIRMA)
Hier wird vorab die Abfrage a definiert, die die Spalten t,c und f zurück liefert. Darin sind eben alle Computer in allen Firmen mit dem neuesten Zeitstempel aufgeführt. Denk dir das als temporäre Tabelle, die bereits die interessanten Zeilen kennt
Anschließend werden aus der ursprünglichen Tabelle all die Zeilen komplett ausgegeben, deren Zeit, Computer und Firma auch im Ergebnis der Abfrage a auftauchen. (ohne mögliche Dupletten)
Ich habe deine und meine Abfrage mal verglichen, die zu erwartende Laufzeit bei meiner MS SQL-Datenbank bei meiner Abfrage läuft ca 30% schneller als deine Variante.
Andere Möglichkeiten wären Optimieriungen der Datenbankstruktur.
Die für die Abfrage absolut schnellste Lösung wäre eine zweite Tabelle mit identischer Struktur, in der immer nur die neuesten Zeilen drin stehen. Dann verkümmert die Abfrage zu SELECT * FROM tblstatusnew. Man kann sogar der DB beibringen, sich um die Einträge der neuen tabelle zu kümmern, sobald ein neuer Eintrag in die alte, große erfolgt.
Das ist aber auch wieder die Frage, wie wichtig und oft diese Abfrage erfolgt, und wieviel Zeit sie kosten darf. Wenn sich deine 50 Chefs permanent für den Zustand aller 1000 Server mit sekündlichem Updateintervall interessieren, dann kann man sowas machen.
Hallo sweber!
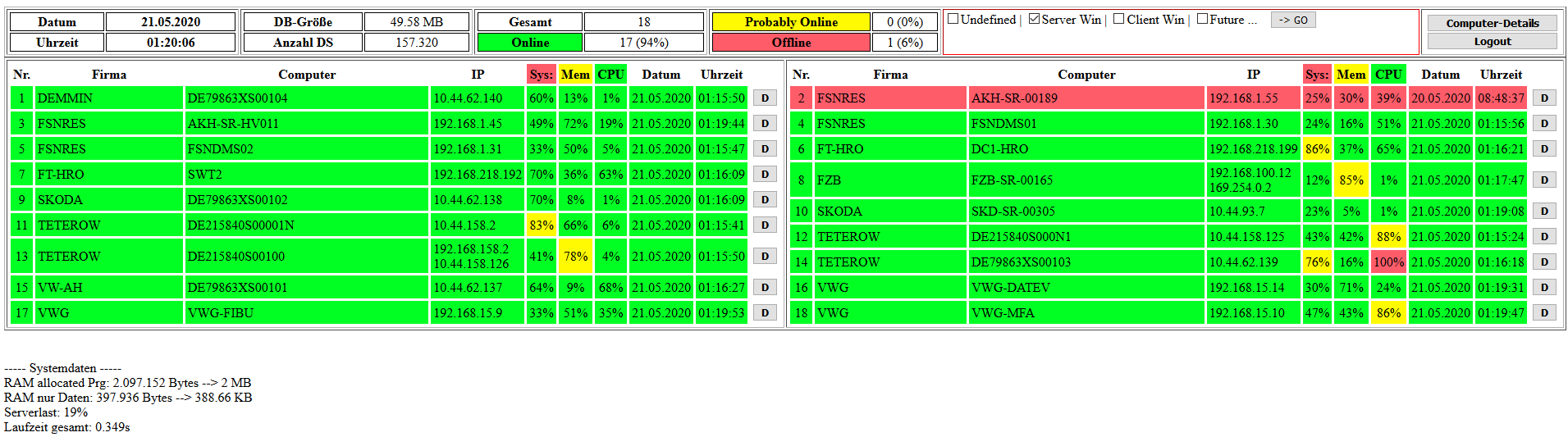
Vielen Dank für die ausführliche und sehr gute Antwort! Du hast mit deinen Annahmen alles genau getroffen! Dein Ansatz ist sehr gut und nachvollziehbar (auch wenn ich selber nicht darauf gekommen wäre). Hier aber noch eine kleine Schwierigkeit: Unter MS-Sql (Windows-Server) läuft das auch wunderbar, aber unter MySql (Strato) nicht (WITH wird wohl nicht unterstützt). Die Anforderungen von der Cheffität sind aber, dass es auf beiden Systemen (mit möglichst minimalen Anpassungen) laufen soll. Einerseits, weil noch nicht sicher ist, auf welchem System es nach der Test- und Anpassungsphase ab November produktiv laufen soll (das System mit der besten Performance gewinnt) und andererseits ist wohl in der Planung, dass es auch verkauft werden soll. Hast du eine Lösung die auf Beidem läuft? Hier noch ein Screenshot (Test-System vom Test-System), was aus den Daten der DB gemacht wird.
MySQL unterstützt WHERE seit Version 8 von April 2018.
Auf meiner kurzen Suche nach der Version bei Strato bin ich haufenweise auf Beiträge von Kunden gestoßen, die sich beschweren, daß strato mit der Bereitstellung neuer Softwareversionen etwas… langsam unterwegs ist. Kann also gut sein, daß die noch lange nicht an Version 8 denken.
Im Grunde wird DB-intern die Abfrage aus dem WITH mit in das JOIN gezogen. Möglicherweise funktioniert es, wenn man das auch direkt so schreibt, ich kann es aber nicht testen, weil ich MySQL aus MariaDB nur privat nutze, und da recht aktuell unterwegs bin.
Hmmm, MySQL 5.6 kam 2013 raus, offizielles End-Of-Life ist Februar 2021, da hat man also noch was Zeit. Aber gut, andere sind noch nicht mal von WinXP weg…
Und was ich grade nicht verstehe… Laut Webseite setzt Strato auf MariaDB, nicht MySQL. Die beiden gleichen sich ziemlich, haben aber eine unterschiedliche Versionsnummerierung. Nach MariaDB 5.5 kam gleich 10.0. Und WITH kam mit MariaDB 10.2.1 von April 2016, der Support geht da noch bis 2022.
Ob es MariaDB oder MySql ist, kriege ich nachher noch raus. Ganz was Anderes: da das mit dem WITH nicht geht, habe ich mal deine Annahme ausprobiert und die Datumsabfrage in die innere Abfrage genommen. Krass! Die Laufzeit des Scripts (und damit die Datenbankabfrage) hat sich fast halbiert! Kann diese Variante mit WITH auch irgendwie mit JOIN oder sowas dargestellt werden?
Ohne es getestet zu haben, entspricht folgendes theoretisch der Abfrage mittels WITH, ich weiß aber nicht, wie es mit der Performance aussieht. Wie gesagt, das WITH sieht aus, als würde es anfangs genau einmal ausgeführt werden, während das hier wieder mehrfach läuft.
SELECT *
FROM tblstatus
RIGHT JOIN a ON (
SELECT
MAX(SQLZEIT),
COMPUTER,
FIRMA
FROM tblstatus as a
WHERE
a.SQLZEIT >= ‚20200416‘ AND
a.c = tblstatus.COMPUTER AND
a.f = tblstatus.FIRMA
GROUP BY FIRMA, COMPUTERa.t = tblstatus.SQLZEIT
)
Aber jetzt nochmal strukturell:
Habt ihr wirklich nur eine einzige Tabelle, in der in jeder Zeile sowohl der Firmenname als auch der Computername steht? Das ist ziemlich ineffektiv! Denn wie viele Zeichen dürfen die beiden Namen jeweils lang sein?
Man würde das besser mit zwei Tabellen realisieren, die eine hat die Spalten Computername, Firmenname, und ID. Und deine Status-Tabelle hat statt Computer- und Firmenname ausschließlich die ID aus der anderen Tabelle als foreign key
Die Vorteile?
Nimm als Datentypen für die ID unsigned INT. Das sind grade mal 4 Byte, die in jeder Zeile der Status-Tabelle benötigt werden, und das reicht für 4,2 Mrd (!) verschiedene Computer.
Es geht deutlich schneller, nach nur einem Feld zu filtern, als nach zweien
Vergleiche zwischen numerischen Werten sind sehr viel schneller als Vergleiche zwischen Zeichenketten
Allerdings werden die Abfragen dadurch ein klein wenig komplizierter.
(Wie kommt das eigentlich, daß du solche Fragen stellst, und deine Firma dieses System verkaufen will? Habt ihr da keinen in der Firma dafür, oder ist das persönlicher Ehrgeiz?)
Hallo sweber! Danke für die Antwort! Habe deine Version getestet und sie läuft so nicht. Meiner Meinung nach fehlt da auch noch was (Definition a.c und a.f), aber die Richtung sieht gut aus. So ganz allgemein zu diesem Projekt: Ich bin nachgeordneter Sys-Admin (gibt noch nen Abteilungsleiter über mir) in nem Autohaus. Keiner von uns Fünfen ist wirklich fit bei Sql, aber die Grundlagen sind da. Wir hatten im Februar einen kompletten Stromausfall und danach war für 2-3 Tage nicht klar, ob alle Server laufen (der externe Dienstleister, der vorher alles gemacht hat, hat natürlich keine Doku rausgerückt). Deshalb habe ich ein Projekt, das ich 2013 mal für ne andere (kleinere) Firma gebaut habe, wieder ausgegraben, um wenigstens irgend etas an Monitoring zu haben. Bei dem alten Projekt ging es um 27 Rechner, jetzt geht es um etwa 70 Server und 380 Clients. Mittlerweile ist es aber auch ein persönliches Ding geworden, was ich zuverlässig zum Laufen bekommen möchte. Nach der Test- und Anpassungsphase soll das Ganze entweder in die Azure-Cloud oder zu Strato gehen, weil der Server für das Monitoring im eigenen Netzwerk keine Sinn macht (selbst wenn Alles ausfällt, möchten wir das sehen können). Alles in einer Tabelle zu halten ist eine Vorgabe von einem Geschäftsführer, der früher wohl mal etwas mit Access gemacht hat. Über den Sinn kann man lange diskutieren, aber das ist jetzt so. Genau dieser Geschäftsführer möchte das auch verkaufen. Na ja, soweit zu den Hintergründen … Bin für jeden Verbesserungsvorschlag dankbar
g